The Data Engineer’s Journal is your go-to resource for the latest insights, tips, and tutorials on data engineering, analytics, and cloud technologies. Whether you're optimizing data pipelines, or exploring cloud platforms, our blog provides actionable content to help professionals stay ahead in the fast-evolving data landscape. Join us on the journey to unlock the full potential of data.
Mastering Spark execution internals is a "must-have" skill for Data Engineers. Whether you are prepping for an interview or debugging a slow production pipeline, understanding how Spark breaks down your code is the key to performance tuning. Spark applications follow a strict hierarchy: Jobs > Stages > Tasks . Let’s break down exactly how this works. 1. High-Level Architecture Before we dive into the code, let’s look at the components that manage the execution: Driver: The brain. It converts your code into a Directed Acyclic Graph (DAG) and schedules tasks. DAG Scheduler: Splits the graph into Stages based on "shuffles." Task Scheduler: Sends the individual Tasks to the executors. Executors: The workers that actually run the tasks in parallel. 2. Real-World Code Walkthrough: The "Wide" Transformation Let’s analyze a common scenario: reading data, filtering, grouping, and saving. # 1. Read Data (Narrow) df = sp...
Get link
Facebook
X
Pinterest
Email
Other Apps
Introduction to Microsoft Fabric - Unified Analytics Platform
Microsoft Fabric is an enterprise-ready, end-to-end analytics platform. It unifies data movement, data processing, ingestion, transformation, real-time event routing, and report building. It supports these capabilities with integrated services like Data Engineering, Data Factory, Data Science, Real-Time Intelligence, Data Warehouse, and Databases.
Fabric provides a seamless, user-friendly SaaS experience. It integrates separate components into a cohesive stack. It centralizes data storage with OneLake and embeds AI capabilities, eliminating the need for manual integration. With Fabric, you can efficiently transform raw data into actionable insights.
Capabilities of Fabric
Microsoft Fabric enhances productivity, data management, and AI integration. Here are some of its key capabilities:
Role-specific workloads: Customized solutions for various roles within an organization, providing each user with the necessary tools.
OneLake: A unified data lake that simplifies data management and access.
Copilot support: AI-driven features that assist users by providing intelligent suggestions and automating tasks.
Integration with Microsoft 365: Seamless integration with Microsoft 365 tools, enhancing collaboration and productivity across the organization.
Azure AI Foundry: Utilizes Azure AI Foundry for advanced AI and machine learning capabilities, enabling users to build and deploy AI models efficiently.
Unified data management: Centralized data discovery that simplifies governance, sharing, and access.
Unification with SaaS foundation
Microsoft Fabric is built on a Software as a Service (SaaS) platform. It unifies new and existing components from Power BI, Azure Synapse Analytics, Azure Data Factory, and more into a single environment.
Fabric integrates workloads like Data Engineering, Data Factory, Data Science, Data Warehouse, Real-Time Intelligence, Industry solutions, Databases, and Power BI into a SaaS platform. Each of these workloads is tailored for distinct user roles like data engineers, scientists, or warehousing professionals, and they serve a specific task. Advantages of Fabric include:
End to end integrated analytics
Consistent, user-friendly experiences
Easy access and reuse of all assets
Unified data lake storage preserving data in its original location
AI-enhanced stack to accelerate the data journey
Centralized administration and governance
Fabric centralizes data discovery, administration, and governance by automatically applying permissions and inheriting data sensitivity labels across all the items in the suite. Governance is powered by Purview, which is built into Fabric. This seamless integration lets creators focus on producing their best work without managing the underlying infrastructure.
Components of Microsoft Fabric
Fabric offers the following workloads, each customized for a specific role and task:
Power BI - Power BI lets you easily connect to your data sources, visualize, and discover what's important, and share that with anyone or everyone you want. This integrated experience allows business owners to access all data in Fabric quickly and intuitively and to make better decisions with data.
Databases - Databases in Microsoft Fabric are a developer-friendly transactional database such as Azure SQL Database, which allows you to easily create your operational database in Fabric. Using the mirroring capability, you can bring data from various systems together into OneLake. You can continuously replicate your existing data estate directly into Fabric's OneLake, including data from Azure SQL Database, Azure Cosmos DB, Azure Databricks, Snowflake, and Fabric SQL database.
Data Factory - Data Factory provides a modern data integration experience to ingest, prepare, and transform data from a rich set of data sources. It incorporates the simplicity of Power Query, and you can use more than 200 native connectors to connect to data sources on-premises and in the cloud.
Industry Solutions - Fabric provides industry-specific data solutions that address unique industry needs and challenges, and include data management, analytics, and decision-making.
Real-Time Intelligence - Real-time Intelligence is an end-to-end solution for event-driven scenarios, streaming data, and data logs. It enables the extraction of insights, visualization, and action on data in motion by handling data ingestion, transformation, storage, analytics, visualization, tracking, AI, and real-time actions. The Real-Time hub in Real-Time Intelligence provides a wide variety of no-code connectors, converging into a catalog of organizational data that is protected, governed, and integrated across Fabric.
Data Engineering - Fabric Data Engineering provides a Spark platform with great authoring experiences. It enables you to create, manage, and optimize infrastructures for collecting, storing, processing, and analyzing vast data volumes. Fabric Spark's integration with Data Factory allows you to schedule and orchestrate notebooks and Spark jobs.
Fabric Data Science - Fabric Data Science enables you to build, deploy, and operationalize machine learning models from Fabric. It integrates with Azure Machine Learning to provide built-in experiment tracking and model registry. Data scientists can enrich organizational data with predictions and business analysts can integrate those predictions into their BI reports, allowing a shift from descriptive to predictive insights.
Fabric Data Warehouse - Fabric Data Warehouse provides industry leading SQL performance and scale. It separates compute from storage, enabling independent scaling of both components. Additionally, it natively stores data in the open Delta Lake format.
Microsoft Fabric enables organizations and individuals to turn large and complex data repositories into actionable workloads and analytics, and is an implementation of data mesh architecture.
OneLake
The Microsoft Fabric platform unifies the OneLake and lakehouse architecture across an enterprise.
A data lake is the foundation for all Fabric workloads. In Microsoft Fabric, this lake is called OneLake. It's built into the platform and serves as a single store for all organizational data.
OneLake is built on ADLS (Azure Data Lake Storage) Gen2. It provides a single SaaS experience and a tenant-wide store for data that serves both professional and citizen developers. It simplifies the user experience by removing the need to understand complex infrastructure details like resource groups, RBAC, Azure Resource Manager, redundancy, or regions. You don't need an Azure account to use Fabric.
OneLake prevents data silos by offering one unified storage system that makes data discovery, sharing, and consistent policy enforcement easy.
OneLake and lakehouse data hierarchy
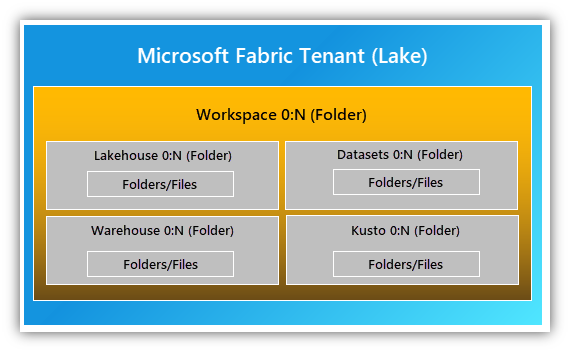
OneLake’s hierarchical design simplifies organization-wide management. Fabric includes OneLake by default, so no upfront provisioning is needed. Each tenant gets one unified OneLake with single file-system namespace that spans users, regions, and clouds. OneLake organizes data into containers for easy handling. The tenant maps to the root of OneLake and is at the top level of the hierarchy. You can create multiple workspaces (which are like folders) within a tenant.
The following image shows how Fabric stores data in OneLake. You can have several workspaces per tenant and multiple lakehouses within each workspace. A lakehouse is a collection of files, folders, and tables that acts as a database over a data lake.
Every developer and business unit in the tenant can create their own workspaces in OneLake. They can ingest data into lakehouses and start processing, analyzing, and collaborating on that data—similar to using OneDrive in Microsoft Office.
Fabric compute engines
All Microsoft Fabric compute experiences come preconfigured with OneLake, much like Office apps automatically use organizational OneDrive. The experiences such as Data Engineering, Data Warehouse, Data Factory, Power BI, and Real-Time Intelligence etc. use OneLake as their native store without extra setup.
OneLake lets you instantly mount your existing PaaS storage accounts using the Shortcut feature. You don't have to migrate your existing data. Shortcuts provide direct access to data in Azure Data Lake Storage. They also enable easy data sharing between users and applications without duplicating files. Additionally, you can create shortcuts to other storage systems, allowing you to analyze cross-cloud data with intelligent caching that reduces egress costs and brings data closer to compute.
The Real-Time hub makes it easy discover, ingest, manage, and consume data-in-motion from a wide variety of sources to collaborate and develop streaming applications in one place.
Watch this video for a walkthrough of the Microsoft Fabric interface and an overview of each experience within Fabric.
Mastering Spark execution internals is a "must-have" skill for Data Engineers. Whether you are prepping for an interview or debugging a slow production pipeline, understanding how Spark breaks down your code is the key to performance tuning. Spark applications follow a strict hierarchy: Jobs > Stages > Tasks . Let’s break down exactly how this works. 1. High-Level Architecture Before we dive into the code, let’s look at the components that manage the execution: Driver: The brain. It converts your code into a Directed Acyclic Graph (DAG) and schedules tasks. DAG Scheduler: Splits the graph into Stages based on "shuffles." Task Scheduler: Sends the individual Tasks to the executors. Executors: The workers that actually run the tasks in parallel. 2. Real-World Code Walkthrough: The "Wide" Transformation Let’s analyze a common scenario: reading data, filtering, grouping, and saving. # 1. Read Data (Narrow) df = sp...
Delta Lake ensures reliable data operations by using optimistic concurrency control (OCC) . This mechanism prevents conflicting writes when multiple jobs or users attempt to update the same table simultaneously. Instead of locking resources, Delta Lake relies on its transaction log and version checks to guarantee consistency. Listen here about conflicting write in Delta Lake What is Optimistic Concurrency Control? Optimistic concurrency control assumes that most transactions will not conflict. Each writer reads the current table state, performs its changes, and then attempts to commit. Before committing, Delta Lake verifies against the transaction log that the underlying data has not changed since the read. If a conflict is detected, the write fails, and the user can retry safely. Why OCC is Better Than Locks Scalability: No need for heavy locking across distributed systems. Performance: Writers proceed in parallel without waiting for locks. Safety...
Understanding Spark Execution: A Deep Dive If you are working with Big Data, writing code that "works" is only half the battle. To truly master Apache Spark, you need to understand how your code is translated into physical execution. Today, let's break down a specific Spark snippet to see how Jobs, Stages, and Tasks are born. The Scenario Imagine we have the following PySpark code: df = spark.read.parquet("sales") result = ( df.filter("amount > 100") .select("customer_id", "amount") .repartition(4) .groupBy("customer_id") .sum("amount") ) result.write.mode("overwrite").parquet("output") Our Cluster Constraints: Input Data: 12 partitions. Cluster Hardware: 4 executors, each capable of running 2 tasks simultaneously. Q1. How many Spark Jobs will be created? Answer: 1 Job. In Spark, a Job is triggered by an Action . Transformations (like filter or groupBy ) are lazy...




Comments
Post a Comment